Welcome to the next in a series of blogs on how we can apply design patterns to everyday development life, rather than just to the code. This time I have chosen the classic Gang of Four ‘Observer’ pattern to look at how we judge the success of agile work and the measures which we base that judgement on.
This blog came out of discussions with David Tanzer on KPIs. Also, thanks are due to Tim Bourguignon who suggested that I include the Observer pattern in the Design Pattern Life Lessons series.
Intent
Defines a one-to-many dependency between a software development and its stakeholders so that when the work changes state, all of its stakeholders are notified.
Motivation
We cannot talk about software development without considering how we measure and report progress to stakeholders. To have a good design means to decouple as much as possible and to reduce the dependencies. The Observer design pattern can be used whenever a software development has to be observed by one or more observers.
Let’s assume we have an agile project which uses story points for estimation. We need to provide information on the progress of the project and the time which the work is likely to take overall. We need to separate the discovery of the velocity by the team from the reporting of the timescales and progress of the project.
Applicability
Use the observer pattern when
- the change of a state in one software development must be reflected in reports to stakeholders without keeping them tightly coupled
- additional stakeholders may be added in the future with minimal changes to existing software developments
Structure
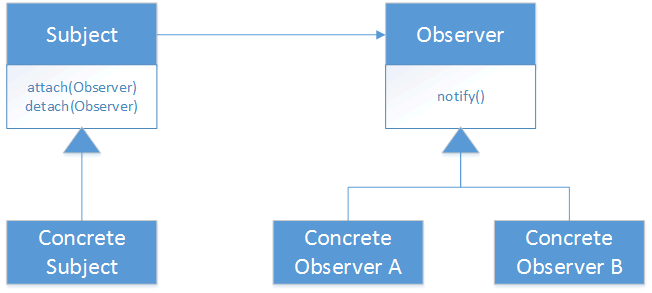
Participants
The objects participating in the observer pattern:
- Subject– the subject to be observed
- ConcreteSubject – concrete class which maintains the state of the software development and when a change in the state occurs it notifies the attached Observers
- Observer – stakeholder for the software development
- ConcreteObserverA, ConcreteObserverB – concrete Observer implementations
Implementation
Progress Measures
In agile projects progress is often measured using velocity. This is flawed in a number of ways:
- velocity is a measure of how much effort we thought it would be to do the work which we have now delivered, rather than a measure of the value of what has been delivered
- velocity is often used as a stick to beat the development team with – if it drops then people want to know why and spend time trying to ‘fix’ the problems in the development team (thus becoming tightly coupled)
One of the worst abuses of velocity which I have seen was on a Scrum project with a failing team. The team knew they were failing, the managers knew they were failing and the other stakeholders also knew they were failing. The team consistently pulled around 45 points worth of work into a Sprint and consistently delivered around 30 points worth of work. This happened Sprint after Sprint. At his wits end the Scrum Master asked me to run a retrospective with the team to work out what was happening.
It turned out that the team knew that they had to deliver 45 points per Sprint because the Scrum Master had calculated that to deliver everything which was needed within the required timescales then the team had to deliver 45 points per Sprint. The team knew this and so consistently tried to bring 45 points worth of work into the Sprint. Rather than discovering the velocity of the team and using that as early feedback for the stakeholders regarding the amount of work which could be achieved within a fixed timescale or the likely time it would take to complete the backlog the Scrum Master had fixed the expected velocity and then berated the team for not achieving it. This wasn’t a failing team – it was a failing Scrum Master.
Process Measures
Process measures are used to look at how well the software development process is serving its customers. As an example consider a team which works on changes which have been requested to existing systems. How well is the process working? How can we tell if a process change has been beneficial?
Lean has two standard process measures, lead time and cycle time. Lead time describes the world as seen by the customer, the time from the enhancement being requested to it being delivered into the live environment. Cycle time describes the world according to the development team, the time between the work being started and it being delivered.

These are both really good measures, but they are limited by the fact that they can only be calculated once the changes have been delivered. They give no view over changes which have not yet been delivered. How many of them are there? How long ago were they requested? How many have we started but not finished?
Limiting work in progress is a key tool for Lean. There are many reasons for this but some of them relevant to this example are:
- the ability to concentrate on one thing at a time increases delivery rate by reducing context switching
- all of the work you have done so far is potential waste – if the changes never go live then the time spent working on them has been wasted
- if there are a large number of changes waiting at various stages of the lifecycle (for example, waiting for UAT resource) then later changes may be built on top of them, making it hard to go live with just the later change or increasing the complexity of source code control
A measure of the amount of work in progress is therefore useful. This could be the amount of time spent so far on each change which hasn’t yet gone live, as this is the amount of time which is potentially wasted. Alternatively it could be a count of the number of requests which have been started but not yet delivered.
How many requests have come in compared to how many requests have been delivered? This gives us some measure if whether we’re keeping up with demand.
How old are the calls which we haven’t yet been delivered? Are there some in there which have been hiding for 5 years?
These types of measures are very useful for working out how efficient our process is. Should we publish them though? They will undoubtedly be used as a stick to hit us with, especially if we are starting from a really bad place. But open and honest communication is central to agile and in order to improve I feel we should be honest about the current state.
Quality Measures
We certainly need to understand the quality of the code so that we can work to improve – but we need to be careful what we measure.
For example, one organisation I worked with had an objective for each of the developers to produce no more than 0.4 bugs per man day. Apart from the fact that this would set up an adversarial relationship between developers and testers you always need to ask yourself how people would game the system. In this case it’s pretty easy – just don’t write any code.
Consequences
Open and honest communication is important, even when the data is embarrassing and doesn’t paint the team in a good light. The measures help the team to identify whether they continuous improvements they make are helping and enable them to fail fast if necessary.
“What gets measured gets managed.” – Peter Drucker
You need to be careful what you measure. How can the measurement be gamed? Does it drive the behaviour you actually want? Does it discourage innovation? Will it be used as a stick to beat the development team with?
I like measurements – but I dislike targets. For me it is about the trends going in the right direction not abut setting an arbitrary target and then measuring success by whether it is met.
See Also
- Design Pattern Life Lessons : Adapter
- David Tanzer’s blog series on KPIs
- Tim Bourguignon’s Dev Journey Project

One thought on “Design Pattern Life Lessons : Observer”